Scraper-copier is a utility I have been working on as a side project. The code is available on Github under the MIT License. Scraper-copier crawls websites and reproduces a web-like folder structure on the user's machine.
If you were to scrap my portfolio using the command :
scraper-copier load https://komlankodoh.com -d ./DestFolder
It would load all the file's links from the provided root link "https://komlankodoh.com" to your local machine. You would then be able to navigate them using your desired file navigator.
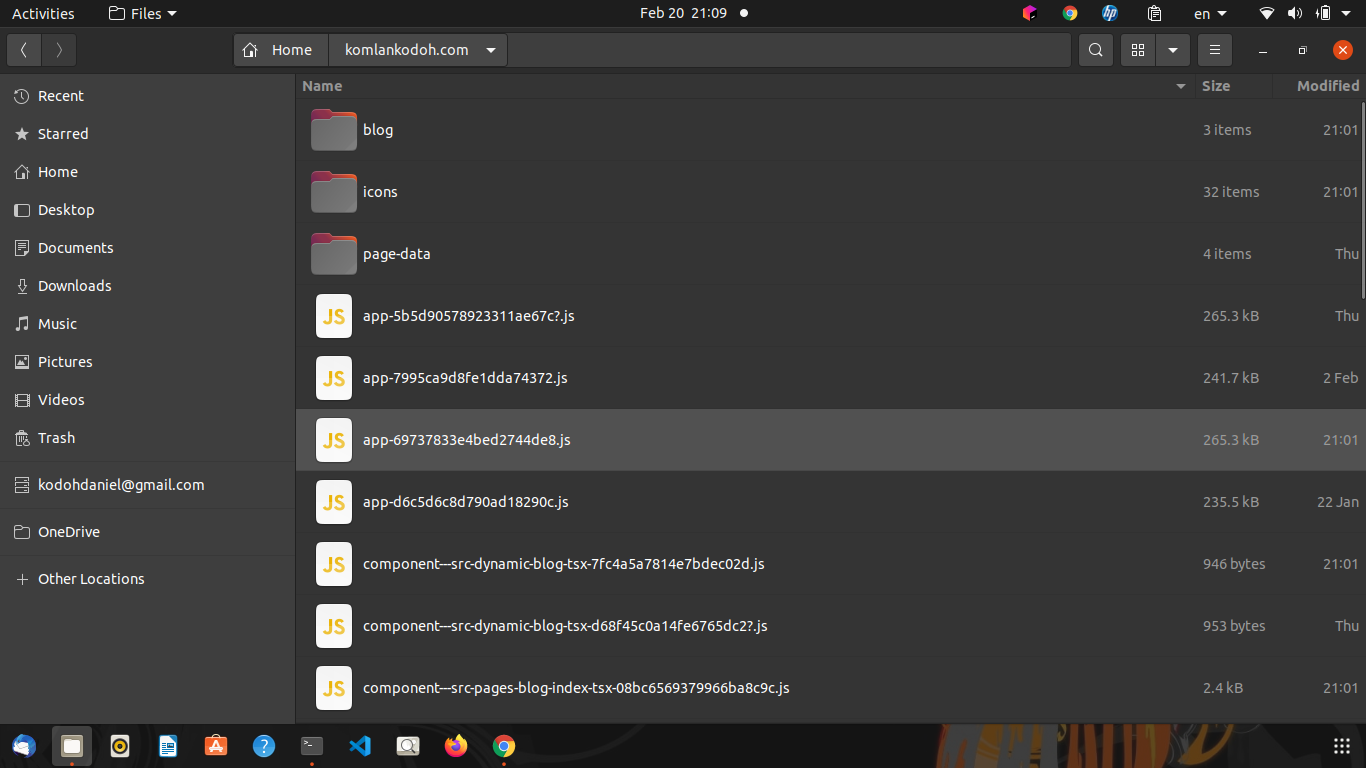
Scrapper-copier can provide good insight on the overall structure of the website and possibly, the tech stack used to create the website.
Project Insights
- Built-in load regulator
Scrapping can be rather aggressive. Most servers define limits related to how many requests a specific IP address can perform ( stack overflow blocked my IP after about 165 successive requests). For those that don't, scrapping could make the response time slower for other users. To prevent these issues, I built a timer that limits the requests rates.
- Query mapping
Most servers accept URL queries. For the most query reliant, a tiny query change could make the difference between getting an image, a JSON, or an Html document. Having that in mind I decided to switch the query present in URLs to right before the file extension. That results in a URL written as "https://randomdata.com/page-data.img?width=400px" to map to "destFolder/randomdata.com/page-data?width=400px.img". This shift is rather necessary for the file system to be able to identify the nature of the file. To allow for operating system compatibility, the query which often contains "illegal" characters is URI escaped before being written to the file system.
- Data Persistence
To allow for data persistence between processes, scraper-copier uses an SQLite database. The process can then use a default database or the one provided by the user via the -d option. When starting a new process the scrapped link database is always flushed unless when explicitly asked to keep the previous data.
Built-in server As a feature, scrapper copier ships with a minimal built-in node js server because "why-not." Assuming you boot the server on port 3000, you can enter a given URL or send an HTTP request to the "https://localhost:3000/proxy?url=REMOTE_URL." to have the server respond with the corresponding ressource.
eg: "https://localhost:3000/proxy?url=https://komlankodoh.com" to get a given resource.Client side routing ( web mock ) Every HTML file written using a scrapper copier receives some javascript that allows for easy (local) routing while using the built-in server. These plugins allow for correct redirections after a link is clicked preventing the user to be redirected to the origin domain if the links clicked target the domain currently served under proxy. All the other requests are redirected to the corresponding external servers.
Lazy caching
The built-in server uses lazy caching which is enabled by default. Lazy caching enables caching the files not found during web scrapping. This could be due to these links only appearing during runtime because generated by some client-side javascript.
Conlusion
Scraper-copier was more than anything a learning adventure. Could it be my early decision to use containers and MySQL or my discovery of the underlying dom APIs and web workers; this project taught me a lot. While the knowledge I gained isn't quite orthodox, I cannot deny the relevance of what I have learned.